The Strategic Imperative of the AI-Powered MVP
By mid-2025, something shifted in how startups build products. The founders who raised seed rounds in 2024 already assume they’ll use AI to build their MVPs. It’s no longer a competitive advantage, it’s table stakes. As we enter 2026, the question isn’t whether to use AI, but how to use it without creating disasters down the road.
The pitch is compelling: embed intelligence from day one, validate concepts faster, gather user feedback earlier, and reach market with a fraction of the traditional engineering resources. For cash-strapped founders racing against their runway, AI promises to compress months of development into weeks.
Why startups are betting on AI-MVPs?
Speed remains the primary draw. A McKinsey study found that developers using GitHub Copilot completed tasks 56% faster than those without the tool—but this applies to proof-of-concept development, not production systems. Once you factor in quality assurance, security reviews, and refactoring, the gains shrink to 15-26% at best. The gap between “works on my laptop” and “ready for 10,000 users” hasn’t disappeared, AI just makes it easier to ignore until it’s too late.
Cost efficiency matters when you’re spending other people’s money carefully. AI-powered MVPs reduce the need for large engineering teams in the validation phase. Instead of hiring five developers at $150K each before knowing if anyone wants your product, you can build with two developers who know how to direct AI effectively. The APIs and low-code platforms handle the undifferentiated heavy lifting, leaving your team to focus on the unique value proposition.
The data story is equally compelling. An AI-powered MVP doesn’t just serve users, it learns from them. Every interaction feeds analytics that would take months to instrument manually. Patterns in user behavior emerge faster. You discover which features matter and which were vanity projects before you’ve burned six months of runway building the wrong thing.
Personalization becomes possible earlier in the product lifecycle. Even at the MVP stage, AI can adapt content and recommendations to individual users. This creates an impression of polish and maturity that’s disproportionate to your actual development time. Users who expect a scrappy beta instead encounter something that feels surprisingly finished.
The hidden bargain
None of these advantages come free. The same AI velocity that lets you ship fast also lets you ship technical debt at unprecedented scale. The security vulnerabilities that would have been caught by a senior engineer’s code review? They’re now baked into your foundation, replicated across dozens of similar functions that AI generated from the same flawed pattern.
You’re making a bet: the speed of validation is worth the cost of remediation later. For some startups, that bet pays off. They find product-market fit, raise their Series A, and hire the engineering team to rebuild on solid ground. For others, the technical debt compounds faster than the business grows, and the MVP becomes an anchor rather than a launchpad.
The next section examines how this velocity trap actually works, and why even experienced developers fall into it.
The Rise of “Vibe Coding” and the AI Velocity Paradox
Developers now start projects differently than they did two years ago. Instead of carefully architecting a solution, they open ChatGPT or Cursor, describe what they want in plain language, and watch as functional code materializes in seconds. The industry has a term for it: “vibe coding.”
The appeal is obvious. A junior developer can scaffold an entire authentication system before lunch. What once took a senior engineer three days to build now takes thirty minutes and a well-crafted prompt. But speed has a price.
Trevor Stuart, SVP and GM at Harness, calls this the “AI Velocity Paradox“: teams write code faster, but ship it slower and with greater risk. Individual developers feel productive, yet organizational delivery slows down. According to Harness’s September 2025 study of 900 engineers across four countries, 45% of deployments involving AI-generated code lead to problems, and 72% of organizations have already suffered at least one production incident from AI-generated code.
The productivity illusion
Ask developers how much faster AI makes them, and they’ll say 10-20%. The feeling of acceleration is real, autocomplete suggestions flow, boilerplate disappears, and the cognitive load lightens. But measurement tells a different story. A July 2025 study by METR tracked 16 experienced open-source developers working on their own mature projects. When allowed to use AI tools, they completed tasks 19% slower than without AI, primarily due to review overhead and debugging AI-specific bugs. The researchers found something remarkable: even after experiencing this slowdown, developers still believed AI had made them 20% faster.
The immediate feedback loop is seductive. Code appears quickly, tests pass, and pull requests get merged. Teams sprint forward, focusing on output velocity over structural integrity. Security becomes an afterthought. The authentication bypass that an experienced developer would catch in code review? It looks correct enough to ship.
What gets lost
Consider what happens when AI generates a password hashing function. The code compiles. It runs. It even produces a hash. But the AI chose MD5 because it appeared frequently in its training data, most often in legacy codebases from 2010. A human reviewer catches it only if they’re specifically looking for it, and only if they haven’t already approved a dozen other AI suggestions that morning and developed review fatigue.
The principle is clear: AI excels at generating small, well-defined functions, but the moment code is introduced that no human on the team fully understands, it becomes unmaintainable by its very nature.
The hidden cost
Vibe coding trades long-term maintainability for short-term velocity. When a startup races toward product-market fit, this tradeoff feels acceptable. The technical debt accumulates silently: duplicated logic, untested edge cases, security vulnerabilities that won’t manifest until the system is under load. By the time the MVP gains traction and needs to scale, the foundation is already compromised.
Hitting the Wall: The Scaling Challenges of an AI-Generated MVP
The problems don’t announce themselves. Your MVP is gaining traction, users are signing up, and investors are interested. Then someone on the team tries to add a seemingly simple feature (say, two-factor authentication) and discovers that the authentication logic is duplicated across seven different files, each with slight variations. Nobody knows which version is correct. The original developer who prompted the AI to generate it left three months ago. The AI can generate seven more versions, but it can’t tell you which of the existing ones should be the source of truth.
This is where technical debt stops being an abstract concept and starts costing real money.
The Maintainability Collapse
GitClear analyzed 211 million lines of code written between 2020 and 2024. Their findings quantify what engineering teams already feel: something broke in how we write software.
Code churn (the percentage of code rewritten or deleted within two weeks of being written) has doubled. In 2021, before AI coding assistants went mainstream, only 3-4% of code was churned. By 2023, that number hit 5.5%. Think about what this means: one in twenty lines of code your team writes this month will be wrong enough that someone has to fix or delete it by month’s end.
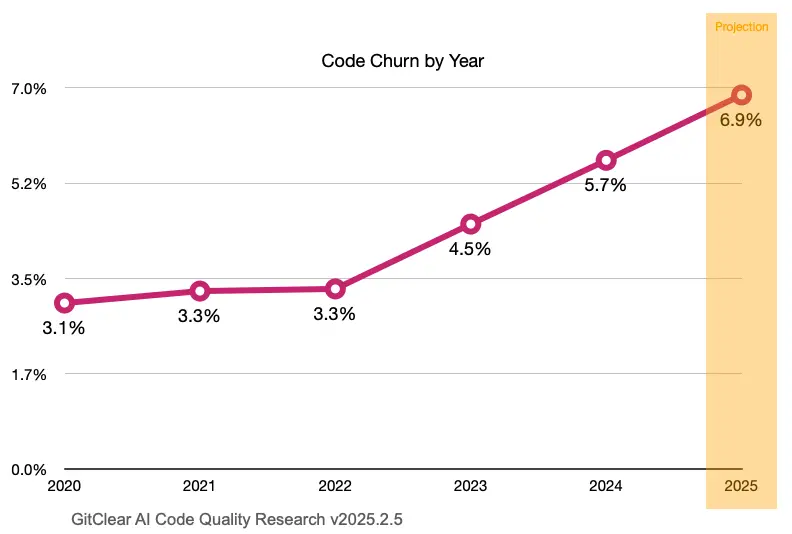
Code duplication increased by 4x. More specifically, GitClear found an 8-fold increase in code blocks where five or more consecutive lines are copied from elsewhere in the codebase. AI models don’t refactor, they generate. When you ask for a function to validate email addresses, the AI doesn’t check if one already exists. It creates a new one. Ask five different developers to add email validation in five different places, and you’ll get five different implementations, each with its own edge cases and bugs.
For the first time in software engineering history, developers now copy-paste code more often than they refactor or reuse it. The “Don’t Repeat Yourself” principle that every junior developer learns in their first week? It’s dying at scale.
Cyclomatic complexity is soaring. AI-generated functions often contain deeply nested if-else chains that work for the happy path but become unmaintainable labyrinths when edge cases emerge. A human developer writes a 20-line function with three conditional branches. An AI generates a 60-line function with eleven branches because it optimized for handling every possibility it could imagine, including several that will never occur in your specific application.
The Quality Crisis
The code runs. The tests pass. Users can complete workflows. But look closer, and the cracks appear.
Functional bugs are the most common issue. The AI writes syntactically correct code that does something other than what you intended. You ask for a function to calculate shipping costs based on weight and distance. The AI generates code that works perfectly for packages under 10 pounds going less than 100 miles. Nobody notices until a customer tries to ship a 50-pound item across the country, and the function returns a negative number.
Reliability bugs emerge under load. The AI-generated code works fine in development with ten test users. It falls apart in production with 10,000 concurrent users because the AI didn’t consider connection pooling, race conditions, or memory management. The code doesn’t crash immediately, it degrades slowly, becoming less responsive until it stops responding at all.
System bugs hide in the details. Memory leaks from unclosed connections. Infinite loops triggered by unexpected input. Buffer overflows that work fine until someone submits a form field with 10,000 characters instead of 100.
The most insidious problem isn’t the bugs themselves, it’s how they get validated. Teams now use AI to generate tests for AI-generated code. The authentication bypass doesn’t get caught because the tests verify that the bypass works as coded, not that it should exist. You’re testing what the code does, not what it should do. This creates a false sense of security that collapses the moment the system faces real-world use.
The Security Nightmare
Security researchers have been sounding alarms for two years, and the numbers keep getting worse.
The Pearce et al. study at NYU tested GitHub Copilot on 89 different security-relevant scenarios, generating 1,689 programs. They found that 40% contained vulnerabilities, SQL injection, cross-site scripting, authentication bypasses, all the classics. These aren’t subtle zero-day exploits. These are mistakes that experienced developers learned to avoid in 2010.
More recent Veracode research analyzing over 100 LLMs found that 45% of AI-generated code fails security tests. Gartner predicts that by 2027, at least 30% of application security exposures will result from vibe coding practices.
Why does AI generate insecure code so consistently? Training data. The models learned from public GitHub repositories, which are filled with buggy, insecure legacy code. When you ask an AI to generate authentication logic, it might pull patterns from 2012 when bcrypt wasn’t standard, or from 2008 when developers hardcoded credentials into source files because “it’s just an internal tool.”
The AI doesn’t understand that those patterns were mistakes. It just knows they appeared frequently in the training data.
The business impact is direct: Your startup can’t pass a security audit. Enterprise customers won’t sign contracts. Insurance providers won’t cover you. Regulators start asking questions. The technical problem becomes a business-ending crisis.
What Comes Next
The pattern is predictable. Startups race to product-market fit on AI-generated code, find traction, then hit the wall when they try to scale. The next section outlines how to avoid this trap, or escape it if you’re already caught.
The Path to Production: A Framework for Maturing the AI-Powered Product
You can’t refactor your way out of this. The technical debt is structural, not cosmetic. Fixing it requires changing how your organization thinks about AI-generated code, not just how individual developers use it.
Three companies illustrate the fork in the road. Company A ignores the problem, ships fast, raises a Series A on impressive user growth, then spends eighteen months and $3M rebuilding the entire platform because enterprise customers won’t accept the security posture. Company B sees the warning signs, pumps the brakes, and systematically hardens the codebase, but loses momentum to competitors who keep shipping. Company C builds governance into their process from day one, moves almost as fast as Company A, but doesn’t have to rebuild later.
The difference isn’t technical sophistication. It’s organizational discipline.
Building AI Governance That Actually Works
Most governance frameworks fail because they’re designed by committees who’ve never written a line of code. They create bottlenecks, slow down velocity, and get bypassed within a month. Effective AI governance needs to be lightweight enough that developers don’t route around it, but robust enough to catch disasters before they ship.
Start with visibility. You can’t govern what you can’t see. Every piece of AI-generated code needs to be tagged as such in your version control system. Not for blame but for understanding. When a security vulnerability emerges six months from now, you need to know whether it came from a human or an AI, and which prompt generated it. This isn’t about surveillance; it’s about root cause analysis.
Risk management happens in production, not in planning. Deploy monitoring that watches for model drift, data quality shifts, and logical deviations in real-time. When your AI-generated recommendation engine starts suggesting products with 1-star reviews, you want to know within minutes, not weeks. Set up alerts for anomalous patterns: sudden spikes in error rates, unusual latency, unexpected database queries. These are early warning signs that AI-generated code is behaving unexpectedly under real-world conditions.
Explainability becomes critical at scale. When your AI-powered credit decisioning system denies a loan application, can you explain why? Not with “the AI decided”, with actual factors that influenced the decision. Regulators don’t accept black boxes. Neither should your executive team. If you can’t explain a decision, you can’t defend it, and you definitely can’t debug it when it goes wrong.
Accountability requires naming names. Who owns the AI-generated authentication system? Not “the engineering team”, which engineer? When the EU AI Act or similar regulations require documentation of your AI systems, which product manager is responsible for maintaining that documentation? Vague collective ownership means nobody owns anything. Assign specific humans to specific systems.
Lifecycle oversight prevents the slow rot. AI models aren’t like traditional code, hey degrade over time as the world changes around them. The sentiment analysis model trained on 2023 social media data starts failing in 2025 when language patterns shift. Schedule quarterly reviews of every AI system in production. Document when they were deployed, what data they were trained on, and when they need to be retired or retrained.
Quality Metrics That Matter
“Clean code” is a feeling. Production incidents are facts. The shift from MVP to production-ready system requires replacing subjective assessments with objective measurements.
Three metrics cut through the noise:
Defect density tells you where the fires are burning. Measure confirmed bugs per 1,000 lines of code, module by module. You’ll discover that 20% of your modules generate 80% of your production incidents. That 200-line utility function that five different AI sessions contributed to? It has three times the defect density of anything your senior engineer wrote. Now you know where to invest refactoring time.
Traditional approaches relied on gut feel: “This module feels fragile.” Data-driven approaches point directly at the problem: “This module has 8.3 bugs per 1,000 lines, and it’s been modified 47 times in the last month. Fix it now before it causes an outage.”
Code churn predicts future problems. When the same file gets modified repeatedly within a short timeframe, it’s usually because nobody understood it properly the first time. Track modification frequency at the file level. Files touched more than five times in two weeks are warning signs. Files touched more than ten times are emergencies waiting to happen.
A payment processing module that gets modified twice in six months is stable. One that gets modified seven times in two weeks is probably AI-generated, poorly understood, and about to cause a billing incident that costs you customer trust.
Mean time to resolution (MTTR) for security vulnerabilities measures your organization’s immune system response. When a researcher reports an SQL injection vulnerability, how long until you’ve patched it, tested the fix, and deployed to production? Industry average is 38 days. Best-in-class teams hit 72 hours. The difference between those numbers is whether you’re ready for enterprise customers or still in startup mode.
Track MTTR by severity. Critical vulnerabilities (remote code execution, authentication bypass) should be measured in hours, not days. Lower-severity issues can wait for the next sprint, but they still need tracking. The pattern matters more than individual incidents. If your MTTR is trending up over time, your technical debt is compounding faster than your team can address it.
Here’s how these metrics translate to production readiness:
| Metric | What It Measures | Why It Matters |
| Defect Density | Confirmed bugs per 1,000 lines of code | Points to modules that need immediate refactoring, not based on intuition but on actual production incidents |
| Code Churn | How often a file is modified within two weeks | Identifies unstable code before it causes outages, turning reactive firefighting into proactive maintenance |
| Security MTTR | Time from vulnerability report to deployed fix | Measures organizational readiness for enterprise adoption, customers want proof you can respond to threats quickly |
Most startups measure these metrics after they’ve already suffered multiple production incidents. The smart ones instrument from day one and watch for trends before the trends become crises.
Redefining the Developer’s Role
The job description changed, but most job postings haven’t caught up. Developers who thrive in AI-assisted environments look different from those who thrived in 2020.
Context engineering is now a core competency, prompt engineering is just the entry point. Most developers stop at learning to write better prompts. “Build me an authentication system” produces different results than “Build a JWT-based authentication system using RS256, with 15-minute access tokens, 7-day refresh tokens, token rotation on refresh, and rate limiting of 5 failed attempts per IP per minute.”
The second prompt produces better code. But that’s still amateur hour.
Context engineering means managing the entire information environment the AI works within, not just what you ask for in a single prompt, but what context you provide, how you structure it, when you inject it, and how you maintain it across multiple interactions. It’s the difference between asking an AI to “fix this bug” and providing it with: the relevant module’s architecture documentation, the error logs from the last three occurrences, the test suite that’s currently failing, the database schema for the affected tables, and the business requirements that define correct behavior.
Here’s what context engineering looks like in practice:
When building a payment processing system, the naive approach is to prompt the AI: “Create a payment processing function.” The context engineering approach provides the AI with: your company’s fraud detection rules, the specific payment gateway’s API documentation, examples of edge cases that caused chargebacks in the past, your compliance requirements for PCI-DSS, and the existing error handling patterns from your current codebase. Then you ask for the function.
The first approach gets you code that compiles. The second approach gets you code that handles the business scenario where a customer’s card expires during a subscription renewal, their backup payment method fails, and you need to pause service gracefully while maintaining their data and notifying them through the correct channel based on their communication preferences.
Context management becomes critical at scale. As your codebase grows, the AI needs increasingly sophisticated context to generate useful code. A senior developer on a mature project spends 30% of their time curating context: extracting the relevant architecture decisions from six months ago, identifying which existing patterns the new code should follow, documenting the constraints that aren’t obvious from the code itself.
This is why AI-generated code quality degrades as projects mature, developers don’t scale their context engineering practices to match the codebase complexity. They keep writing simple prompts for complex problems, and the AI fills in the gaps with generic patterns that violate unstated architectural principles.
Architecture can’t be delegated to AI. The AI will write whatever function you ask for, but it won’t tell you that you’re building the wrong function. It doesn’t know that your monolithic architecture should be decomposed into microservices, or that your synchronous API calls should be asynchronous, or that you’re about to create a circular dependency that will make the system impossible to test.
Senior developers now spend less time typing code and more time drawing boundaries, defining interfaces, and making architectural decisions that AI can’t make. The value isn’t in the syntax, it’s in knowing what to build and how the pieces fit together. That architectural knowledge becomes the context that guides AI code generation.
Code review becomes the critical gate. Junior developers used to submit code for review, and seniors would catch bugs, suggest improvements, and teach patterns. Now AI submits code at 10x the volume, and humans are the only defense against shipping vulnerabilities at scale.
The review process needs to change. Instead of skimming for obvious bugs, reviewers need checklists: Does this duplicate existing functionality? Does it handle edge cases? Does it follow our security standards? Is it tested against failure scenarios, not just happy paths? Has it been reviewed for compliance with our data handling policies?
Review fatigue is real. When you’re approving your fiftieth AI-generated function of the day, you stop seeing the problems. This is where pair programming with AI breaks down, the human becomes a rubber stamp instead of a filter.
Domain knowledge is the moat, and the most valuable context you can provide. AI models don’t understand your business. They don’t know that insurance claims processing requires different validation rules than e-commerce checkout, or that healthcare data has special retention requirements, or that your financial services customers require audit trails that survive database migrations.
Developers who understand the domain (not just the technology) become force multipliers. They can engineer context that directs AI to generate code solving actual business problems, not just technical ones. They know which corner cases matter and which are theoretical. They understand the regulatory environment and can provide context that guides AI away from patterns that might be technically correct but legally problematic.
This is context engineering at its highest level: translating business requirements, regulatory constraints, architectural principles, and tribal knowledge into structured context that consistently produces production-ready code.
Moving Forward
Implementing these three pillars (governance, metrics, and role clarity) doesn’t happen overnight. It’s a journey that takes most organizations 6-12 months to complete. But the alternative is worse: watching your technical debt compound until the system becomes unmaintainable and you’re forced into a complete rebuild.
The final section explores what this journey looks like in practice.
The Strategic Choice Ahead
The AI velocity paradox isn’t going away. If anything, it’s accelerating. As models get better at generating code, the gap between “shipping fast” and “shipping well” will widen, not narrow. Every startup entering 2026 will face the same choice: accept the technical debt as the cost of speed, or build governance that allows you to move fast sustainably.
There’s no right answer, only tradeoffs you need to understand before you make them.
If you’re pre-product-market fit, bias toward speed. Build the MVP in two weeks instead of two months. Use AI to test ten ideas instead of one. Accept that 40% of your code might have security vulnerabilities because you’re probably going to throw away the entire codebase anyway when you pivot. The technical debt doesn’t matter if the company doesn’t survive to pay it back.
But know what you’re signing up for. When you find product-market fit, and if you’re lucky enough to find it, you’ll face a reckoning. The authentication system you built in an afternoon won’t pass a security audit. The database schema that works fine for 100 users will collapse at 10,000. The payment processing logic that handles happy paths will fail catastrophically on edge cases that real customers encounter daily.
You’ll have a choice: rebuild from scratch (expensive, slow, demoralizing) or incrementally harden the codebase (grinding, frustrating, never quite done). Most companies choose the second option and spend the next year fighting fires instead of building features.
If you’ve found product-market fit, the calculus changes. Now you’re not exploring, you’re scaling. The technical debt stops being an acceptable tradeoff and becomes an existential risk. Enterprise customers won’t sign contracts with security holes. Compliance audits fail systems with unexplainable AI decisions. Outages caused by poorly understood AI-generated code destroy trust faster than feature velocity builds it.
This is where context engineering, governance frameworks, and quality metrics shift from “nice to have” to “business critical.” You need visibility into what code is AI-generated, monitoring for when it behaves unexpectedly, and processes to catch vulnerabilities before they ship. You need developers who understand that their job is now curating context and reviewing output, not writing syntax. You need architects who can make decisions that AI can’t make.
The companies that figure this out early (that build governance into their DNA from day one) don’t just survive the transition from MVP to production. They thrive. They move almost as fast as the cowboys shipping recklessly, but they don’t accumulate the technical debt that eventually forces a rebuild.
The 2026 startup ecosystem will split into two tiers. The first tier will be companies that learned to harness AI without being consumed by it. They’ll ship fast, scale efficiently, and pass enterprise security audits. They’ll raise Series B rounds because they can credibly claim to be ready for growth.
The second tier will be companies that shipped faster than they could understand what they were shipping. They’ll raise Series A on impressive user metrics, then stall out when enterprise customers demand security guarantees they can’t provide. They’ll spend their runway rebuilding systems that should have been built correctly the first time. Some will survive the transition. Most won’t.
Which tier you end up in is decided in the first six months. Not by your technology choices or your team’s raw talent, but by whether you treated AI as a productivity tool or a replacement for engineering discipline. The developers who prompt without providing context. The teams that skip code review because they’re moving too fast. The founders who see technical debt as someone else’s problem.
These decisions feel small in the moment, one shortcut, one skipped review, one more AI-generated function merged without proper scrutiny. But they compound. The codebase that takes three days to build can take three months to understand and thirty months to rebuild correctly.
Here’s what success looks like in practice:
A startup raises a seed round in January 2026 and builds their MVP in three weeks using Claude to generate most of the code. But they also implement basic governance: every AI-generated function gets tagged in version control, every merge request requires human review with a security checklist, and every module has ownership assigned to a specific engineer who’s accountable for maintaining it.
By March, they’ve found product-market fit. User growth is explosive, 10x in six weeks. The technical debt is real, but it’s documented, measured, and managed. They know which modules are fragile because they’ve tracked defect density. They know which code is stable because they’ve measured churn rates. When an enterprise customer asks about their security posture, they can demonstrate governance, not just promise it.
By June, they’re raising a Series A. The due diligence process includes a technical audit. The auditors find vulnerabilities, every codebase has them, but they also find a systematic process for addressing them. MTTR for critical security issues is under 72 hours. The team can explain every architectural decision. The code isn’t perfect, but it’s understood, and it’s improving.
That’s the playbook. Not perfection, but intentionality. Not zero technical debt, but managed technical debt. Not avoiding AI, but using it strategically within guardrails.
The companies that win in 2026 won’t be the ones that shipped fastest in 2025. They’ll be the ones that shipped fast and built the organizational muscle to keep shipping as they scaled. The ones that treated AI as a force multiplier for disciplined engineering, not a replacement for it.
The AI velocity paradox is real. But it’s not destiny. You just have to choose which side of it you want to be on.